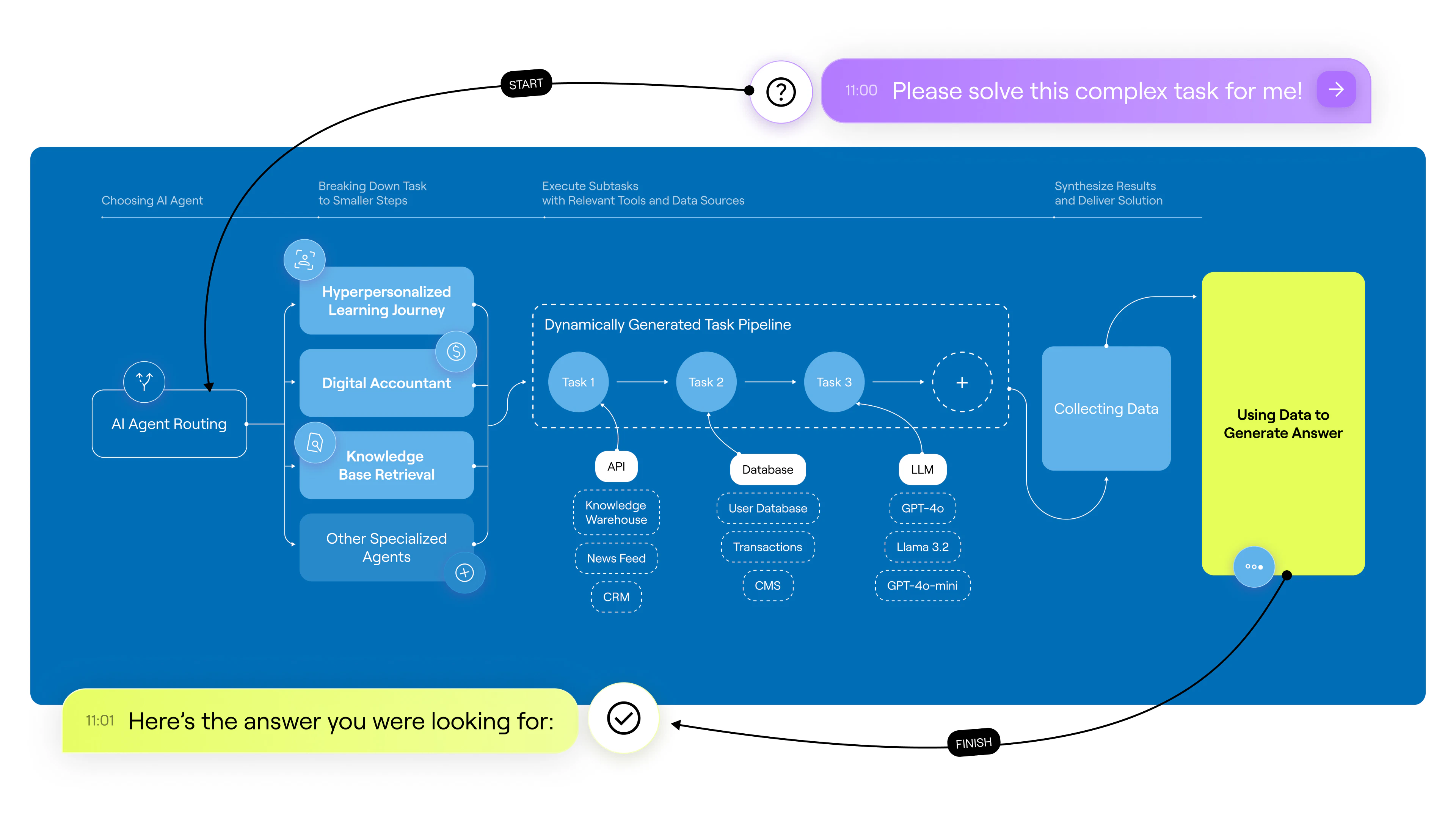
Structure of a Pipeline
Each step in the pipeline follows an Input-Process-Output (IPO) loop with built-in error handling to ensure reliable execution:- Input: Each step starts with input arguments, defined by the tool being used. These arguments, derived from previous steps or initial data, serve as the input for the IPO loop.
- Process: The tool processes the input according to its function, whether retrieving data, performing calculations, or generating a response. A process can be a simple calcultion or an API call or any other classic programmatical task.
- Output: The tool produces a return value as output. This return value is collected by the AI agent, which stores it for use as an argument in the next step of the pipeline, maintaining continuity and data flow across steps.